


About this time last year, Google made the last in a series of six planned changes to Chrome that significantly altered the web landscape behind the scenes. The date was February 7th 2023 and the occasion was the release of Chrome version 110. By design, this release of Chrome coincided with the last step of Google’s “User Agent Reduction” plan and a corresponding User-Agent Client Hints proposal. From that day onwards, rollout of the significant new behaviour by Chrome on mobile devices commenced. The new behaviour had been rolled out the previous year on the desktop version of Chrome.
To recap, UA-CH is a proposed standard from Google whose aim is to remove passively available information from web requests. This is achieved by removing granular information from the standard User-Agent HTTP header and moving to an active model whereby web servers are required to actively request granular details from web browsers rather than getting it by default. The browser can then choose whether or not it wishes to send this granular information in its next request to the web server.
In this article we will take a look at the impact of this change on the web ecosystem in the year since it fully launched.
Impact of UA-CH on the web landscape
At the time of writing, February 2024, most Chromium-based browsers now utilise UA-CH and present with a frozen User-Agent string. This means that, for most websites, a majority of traffic is presenting with frozen User-Agent strings since Chrome alone accounts for approximately 70% of web traffic.
Confusion begins with the letter K
This has caused no small amount of confusion around the web. Any website or service that has not updated its logic will now be exhibiting unexpected behaviours. We've experienced quite a few over the last year. Even Google themselves were tripped up by their own changes, with the Wiko K-KOOL phone suddenly jumping to to the top device in Google Analytics and corresponding step changes in Android version popularity. You can read about some of the confusion here.
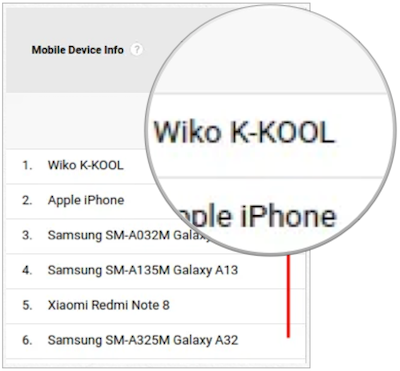
Google Analytics: the little-known Wiko K-KOOL suddenly dominates web traffic
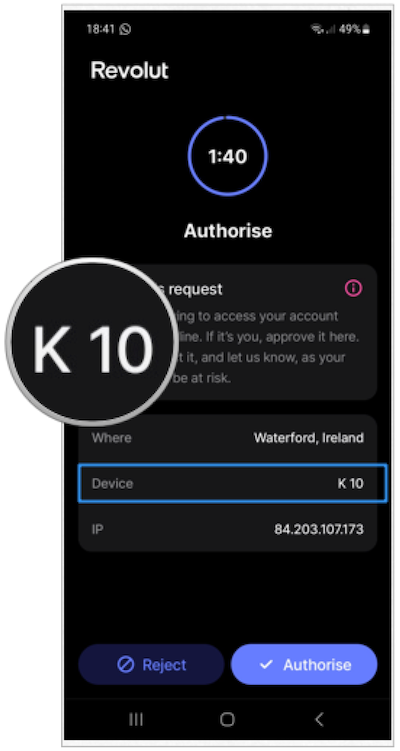
Revolute: your phone is a model K
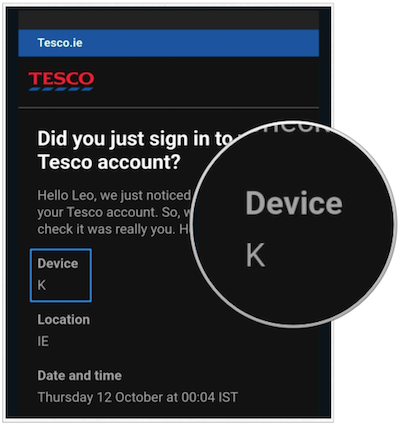
Tesco: your phone is a model K
That so many participants in the web ecosystem were caught unaware should come as no surprise. User-Agent Client Hints went from a proposal in an incubator group to global rollout for the majority of web traffic in just a few years, a breakneck pace for replacing a standard that stood since the dawn of the web, over thirty years ago. Furthermore, the change happened without any of the usual careful consensus building and standards-body oversight normally associated with mechanisms underpinning the internet.
To add to the confusion, the UA-CH proposal appears relatively straightforward on the surface but is surprisingly difficult to deal with in practice. Website operators now have to contend with multiple new considerations, some of which they have little or no control over:
- Handling the difference between a first request and subsequent requests;
- Configuring new response headers on origin servers and CDNs;
- Delegating UA-CH permissions to third-party origins and iframed content.
Browser makers were confused also. We have seen cases where browsers sent self-inconsistent headers i.e. incompatible claims made between the UA-CH headers and the standard User-Agent string—a browser might claim to be running on Windows in one header and Linux in another.
Inevitably, bad actors have taken advantage of the confusion. A new HTTP header presents a new opportunity in the form of new surface area for attacks: web servers are obliged to accept and process these new headers but may not yet be hardened against deliberate abuse of them such as SQL injection attacks.
A complicated dance becomes a game of Twister
The second sentence of the UA-CH Explainer says the following:
"This header's value has grown in both length and complexity over the years; a complicated dance between server-side sniffing to provide the right experience for the right devices on the one hand, and client-side spoofing in order to bypass incorrect or inconvenient sniffing on the other. "
Predictably, the UA-CH proposal has only served to increase the complexity of this dance since the core drivers of this complex behaviour are not solved by the proposal. Instead we are left with multiple additional ways to misconfigure servers …and multiple ever more complex means for trying to bypass this. In other words, the “complicated dance” just got a lot more complex.
There have already been examples of website incorrectly blocking some browsers through misconfiguration of UA-CH headers, with the inevitable result of browser makers having to work around this …and so the cycle continues, though with layers of extra complexity
Developer impact, and the wonderful thing about standards
As Andrew Tanenbaum quipped over forty years ago, the wonderful thing about standards is that there are so many of them to choose from. Google’s UA-CH proposal has achieved exactly this outcome with respect to HTTP headers, greatly increasing the complexity of dealing with headers from user-agents. The result is that, for the forseeable future, developers must implement two entirely different rubrics for dealing with HTTP headers, depending on how a user-agent presents.

To add to the developer load, UA-CHs also turn out to be surprisingly complex to deal with for a three main reasons:
- UA-CH headers are sent only after receiving a response header from the server requesting them, meaning that thay are not available on the first request sent by a browser. This breaks many flows since the information required to render the first page is not available at the time of the first request;
- Permissions around iframes and 3p content are delicate and messy;
- The JavaScript API has two separate methods and uses inconsistent naming.
Have UA-CH achieved their aim?
So UA-CH have certainly had some negative effects, but have they accomplished their stated aim of reducing passive fingerprinting? Maybe it was all worthwhile?
Here at DeviceAtlas we’re certainly not neutral bystanders, so rather than giving you our opinion we would refer you instead to an interesting analysis of UA-CH from two noted privacy researchers from KU Leuven University in Belgium and Radboud University in The Netherlands. In this rich and detailed analysis, the researchers found that, yes, passive collection of identifying browser features is indeed less possible as a result of UA-CH, but that:
"third-party tracking and advertising scripts continue to enjoy their unfettered access."
They they go on to say:
“Our results show that high-entropy UA-CHs are accessed by one or more scripts on 59% of the successfully visited sites and 94% of these calls were made by tracking and advertising-related scripts—primarily by those owned by Google.”
This was exactly our problem with the UA-CH proposal in the first place: it reduced the prevalence of something that nobody was able to demonstrate was a problem (despite multiple requests for evidence), while leaving unsolved the thing that most agree is actually a problem. UA-CH proponents will argue that drawing this behaviour out into the open is a good thing but in an era when most web traffic flows over HTTPS connections the fingerprinting game is all about active fingerprinting and UA-CH doesn't even attempt to solve that aspect.
This was an entirely predictable outcome, which begs the question of why the whole proposal was implemented in the first place. A touch of “privacy-washing” perhaps? Some skepticism doesn't seem misplaced since Google is the last browser company to turn off third party cookies by default amongst many other privacy-hostile behaviours.
It's also possible that the proposal achieved an unstated aim—to tilt the advertising landscape a little in their favour. We are hearing reports that Open RTB participants are seeing a tiny fraction of bids with populated SUA objects (the SUA is the UA-CH equivalent of the UA object). This disproportionately impacts Google's competitors since Google has many other sources for the missing information from their dominance of the browser, mobile OS and web platform spaces—but their competitors do not.
Summary
So, wrapping up, where does all of this leave us? Unfortunately, on this, its first birthday, the vaunted child is falling short of its promise. User privacy hasn't improved meaningfully and the web just became a lot more complicated for implementors—merely maintaining feature parity for users now requires a significantly more effort to achieve and disproportionally impacts smaller players. Adding insult to injury, the situation is unlikely to get better in the foreseeable future.
Here at DeviceAtlas our mission remains unaltered—to deliver fast and accurate device intelligence in a turbulent and complex landscape. Our version 3 SDK continues to offer industry-leading intelligence regardless of what standards browser makers choose to adopt, insulating our customers from the capricious web landscape.