

Updated: March 2023
Allowing web crawlers to scan your site is vital if you want your web pages to appear in Google, Bing and other search results. However, unwanted traffic spikes caused by non-human visitors can be costly in terms of bandwidth, CPU time, website stability, potentially leading to site outages.

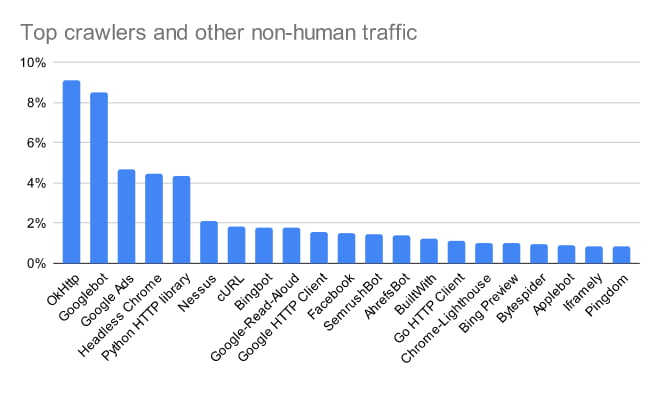
We've just updated our list of most active web crawlers, bots and spiders visiting websites, i.e. the most common instances of non-human traffic that we see in our data. We have also included their user-agents for reference. It's important to note that this list only includes bots which identify themselves; to learn about both self-declared and undeclared bots visiting websites, check out these articles Introduction to Bot Traffic — Part One of our Bot Analytics Series and Dark Traffic and Misrepresentation - Analyzing the Web Analysers (Part 2).
Highlights from the article
- User Agent Client-Hints supported only by few crawlers
- Android dominates mobile crawling traffic
- The HTTP libraries between the most active crawlers
- Mid tier "devices" used for the crawling (mostly from 2016)
- Almost no crawlers using tablet User-Agent
What are crawlers used for?
Web crawlers, also known as web spiders or bots, are automated programs used to browse the web and collect information about websites. They are most commonly used to index websites for search engines, but are also used for other tasks such as monitoring online content, validating HTML code, testing web performance and feeding language models.
Web crawler engine
The most common crawlers hitting any site are in-house scraping engines like Google, Bing or DuckDuckGo. Those engines include the ability to scale, sophisticated logic to crawl the site without causing any impact and to store and process massive data sets.
There are also many open source engines available with interesting features such as ability to simulate human behavior, rate control, distributed architecture or parsing of various document formats.
- In-house
Google, Bing, Yahoo, DuckDuckGo and others… - Open source
Scarpy, Pyspider, Crawlee, Heritrix, Web-Harvest, Apify, MechanicalSoup, Apache Nutch, Node Crawler and many, many more… - HTTP library
OkHttp, Java, PHP, Python, NodeJS… - Command line tools
Wget, cURL (also integrated as a library by other languages)
Crawlers list
Names of the most active crawlers, bots and other non-human traffic on the web as seen by our device detection Cloud Service. It is not to be interpreted as traffic directly due to the caching mechanism used by the Cloud Service clients which might favor services using various User-Agent versions. It’s a combination of normalized traffic and “popularity” of the crawlers within our user base.
| Crawler Name | Purpose / engine | Official homepage |
|---|---|---|
| Googlebot | Search engine, checker and many other services | Google crawlers |
| OkHttp library | HTTP library for Android and Java applications | OkHttp |
| Headless Chrome | Browser operated from command line / server environment | Headless Chromium |
| Python HTTP library | HTTP libraries like Requests, HTTPX or AIOHTTP | Python Requests |
| cURL | Command line tool and a library | cURL |
| Nessus | Vulnerability scanner | Nessus |
| Social network / previews | Facebook Crawler | |
| Bingbot | Search engine | Bing crawlers |
| AhrefsBot | Site and Marketing Audit | AhrefsBot |
| SemrushBot | Site Audit | SemrushBot |
| Chrome-Lighthouse | Browser addon, auditing | Lighthouse |
| Adbeat | Site and Marketing Audit | Adbeat |
| Comscore / Proximic | Online Advertising | Comscore Crawler |
| Bytespider | Search engine | 关于Bytespider |
| PetalBot | Search engine | Petal Search |
User-Agents of most active crawlers
OkHttp library
Not a crawler as such but the most spread HTTP library generating non-human traffic. Each request might have a different purpose as anybody can incorporate this library by their own means. The most popular variant seems to be version 4.9.2 and version 3.12.10 where the latter one is around two years old.
| Popular User-Agent variants | Traffic proportion |
|---|---|
| okhttp/3.12.10 | 40 % |
| okhttp/4.9.2 | 35 % |
There is no surprise that most crawling requests are coming from Google bots. That includes Googlebot, Google Ads bot, Google-Read-Aloud bot and others. Some of them even include two variants - desktop and mobile.
Beware that due to its popularity there might be other services pretending to be the Googlebot or there might be individuals trying to get past the paywalls.
| Google User-Agent samples | Service / Crawler |
|---|---|
| Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Googlebot |
| Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.130 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Googlebot Mobile |
| AdsBot-Google (+http://www.google.com/adsbot.html) | Google Ads Bot |
| Mozilla/5.0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36 (compatible; Google-Read-Aloud; +https://support.google.com/webmasters/answer/1061943) | Google Read Aloud |
Headless Chromium
Headless Chromium allows running Chromium in a headless/server environment. Expected use cases include loading web pages, extracting metadata (e.g., the DOM) and generating bitmaps from the page contents.
e.g. Used for the PageSpeed Insights service
| Headless Chromium User-Agent samples | Environment |
|---|---|
| Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/104.0.5112.101 Safari/537.36 | Linux |
| Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/100.0.4896.127 Safari/537.36 | Windows |
The Facebook crawler which prefetches a page to generate a preview of the page which usually consist of title, short description and thumbnail image.
| Facebook User-Agent sample |
|---|
| facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
Python
| Python User-Agent samples | Library |
|---|---|
| python-requests/2.28.1 | Requests |
| Python/3.8 aiohttp/3.8.1 | AIOHTTP |
| python-httpx/0.23.3 | XHHTP |
| Python-urllib/2.7 | python-urllib |
| python-urllib3/1.26.12 | python-urllib3 |
Nessus
| Nessus User-Agent samples |
|---|
| Nessus |
| NESSUS::SOAP |
| Nessus/190402 |
cURL
| Popular User-Agent variants | Traffic proportion |
|---|---|
| curl/7.58.0 | 21.7 % |
| curl/7.47.0 | 10.6 % |
| curl/7.68.0 | 10.2 % |
Bing
| Bing User-Agent samples |
|---|
| Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/103.0.5060.134 Safari/537.36 |
| Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Mozilla/5.0 (iPhone; CPU iPhone OS 7_0 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A465 Safari/9537.53 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534+ (KHTML, like Gecko) BingPreview/1.0b |
Others to note
| User-Agent samples | Crawler |
|---|---|
| Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 GLS/92.10.4949.50 | Google HTTP Java Client |
| Mozilla/5.0 (compatible; SemrushBot; +http://www.semrush.com/bot.html) | SemrushBot |
| Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) | AhrefsBot |
| Mozilla/5.0 (Linux; Android 7.0; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4590.2 Mobile Safari/537.36 Chrome-Lighthouse | Chrome-Lighthouse |
| Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot) | Bytespider |
| Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot) | Applebot |
| Pingdom.com_bot_version_1.4_(http://www.pingdom.com/) | Pingdom |
| axios/0.27.2 | Axios |
| Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) | YandexBot |
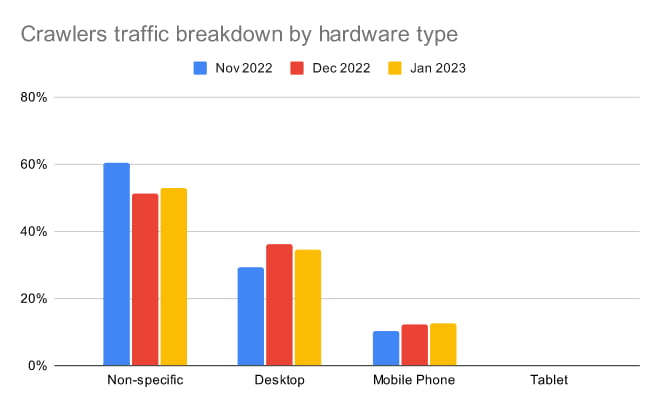
Crawlers by hardware type
There are many ways we can categorize non-human traffic. It can be by their purpose, it can be by their engine, as already mentioned above or it can be by how they advertise themselves to the websites.
Crawlers can use non-specific keywords in the User-Agent - having just their own name as the pivotal point - or they can pretend to come from a specific hardware like desktop, mobile phone or tablet.
Client-Hints support
Even though it is primarily Google who wants to deprecate and freeze User-Agent their Googlebots fleet was left behind. The mobile bots still rely on the classic User-Agent parsing without any “sec-ch” headers. We tried to reach out and asked about crawler’s Client-Hints support but there was no reply.
So far it’s only such non-human traffic which functions as a proxy, like Amazon CloudFront, or using a real Chrome engine, like Chrome-Lighthouse, HeadlessChrome or SpeedCurve, which support Client-Hints. There is zero Client Hints support from all the rest.
Amazon CloudFront HTTP headers sample
sec-ch-ua: "Not_A Brand";v="99", "Google Chrome";v="109", "Chromium";v="109" sec-ch-ua-mobile: ?1 sec-ch-ua-platform: "Android" user-agent: Amazon CloudFront
Chrome-LightHouse HTTP headers sample
sec-ch-ua: "Chromium";v="98", "Google Chrome";v="98", "Lighthouse";v="9.6.6" sec-ch-ua-mobile: ?1 sec-ch-ua-platform: "Android" user-agent: Mozilla/5.0 (Linux; Android 7.0; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4590.2 Mobile Safari/537.36 Chrome-Lighthouse
SpeedCurve (PTST) HTTP headers sample
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="109", "Google Chrome";v="109" sec-ch-ua-mobile: ?1 sec-ch-ua-platform: "Android" user-agent: Mozilla/5.0 (Linux; Android 8.1.0; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36 PTST/230125.191541
Headless Chrome HTTP headers sample
sec-ch-ua: sec-ch-ua-mobile: ?0 sec-ch-ua-platform: user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/104.0.5112.101 Safari/537.36
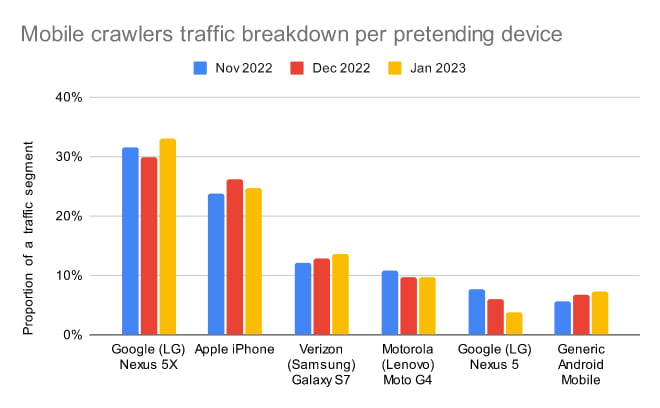
Mobile crawlers
Here is a special breakdown of a traffic where crawlers are pretending to be a specific mobile device or a tablet. Overall it’s the Android models that dominate crawling part of the traffic, regardless of Apple's policy of the model obfuscation in the User-Agent.
Reference mobile phones
There seems to be no real demand to use the most up-to-date mobile devices. All the crawler User-Agents have been picked and set many years ago and it’s working as expected. Pretty well representing the mid tier mobile device category.
Let’s look at most popular devices to see what mobile devices have been picked by crawling giants and for what functionality, image size and screen dimensions optimize non-human traffic.
Google (LG) Nexus 5X
- Proportion of reference traffic: 30 % - 33 %
- Reported Android version: 6.0.1
- Year released: 2015
- Viewport width: 412 (1080 physical)
- Diagonal screen size: 5.2”
- Processor: Hexa-core (1.8 GHz, 1.4 GHz)
- Used by Google
Google Nexus 5X can be called a reference Android mobile phone. Decent physical screen resolution supporting Full HD, six cores and 5.2” diagonal screen size. Along with the Apple iPhone it is accounting for the majority of the crawlers traffic pretending to be a mobile device.
Heavily used by various Google crawling services or by other crawlers pretending to be Google. The Android version seems to be fixed at 6.0.1 while Chrome browser versions are getting updated, at least for the official Google bot User-Agents.
| Nexus 5X crawler User-Agent samples |
|---|
| Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.130 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.5414.74 Mobile Safari/537.36 (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html) |
| Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Google-Safety; +http://www.google.com/bot.html) |
Apple iPhone
- Proportion of reference traffic: 24 % - 26 %
- Reported iOS version: 6.0 - current
- Year released: 2009 (iPhone 3GS) - current
- Viewport width: Anything from 320 to 430 (640 to 1290 physical)
- Diagonal screen size: Anything from 3.5” to 6.69”
- Processor: Anything from Single-core (600 MHz) to Hexa-core (3.46 GHz)
- Used by Google, Semrush, Bing, Yisou, Baidu and many others
Despite the iPhone User-Agent being used the most by the mobile crawlers it’s actually the most difficult one for the content optimisation. Lack of a specific model makes the optimization very hard due to the performance and screen resolution quite big differences across the whole iPhone product line.
| Apple iPhone crawler User-Agent samples |
|---|
| Mozilla/5.0 (iPhone; CPU iPhone OS 14_7_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Mobile/15E148 Safari/604.1 (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html) |
| Mozilla/5.0 (iPhone; CPU iPhone OS 7_0 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A465 Safari/9537.53 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; SiteAuditBot/0.97; +http://www.semrush.com/bot.html) |
Verizon (Samsung) Galaxy S7
- Proportion of reference traffic: 12 % - 13 %
- Reported Android version: 7.0
- Year released: 2016
- Viewport width: 360 (1440 physical)
- Diagonal screen size: 5.1”
- Processor: Quad-core (2.16 GHz, 2.15 GHz)
- Used by Google
The Google Read Aloud service seems to be popular enough to trigger many requests pretending to be a Verizon Galaxy S7 mobile device and end up as the third most popular crawler mobile device across the Cloud Service user base.
There seem to be only single User-Agent in-use with fixed Android version and also fixed Chrome browser version. Either this service “crawling” part is working seamlessly and doesn’t require any updates or it’s not in the spotlight as it is not directly generating any revenue.
Why Google is using a branded Verizon model variant (SM-G930V) and not a “generic” unlocked model version (SM-G930U) is not fully clear.
| Galaxy S7 User-Agent sample |
|---|
| Mozilla/5.0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36 (compatible; Google-Read-Aloud; +https://support.google.com/webmasters/answer/1061943) |
Motorola (Lenovo) Moto G4
- Proportion of reference traffic: 9 % - 11 %
- Reported Android versions: 6.0.1, 7.0 and 8.1.0
- Year released: 2016
- Viewport width: 360 (1080 physical)
- Diagonal screen size: 5.5”
- Processor: Octa-core (1.5 GHz, 1.2 GHz)
- Used by Chrome-Lighthouse and SpeedCurve WebPage Test
The Moto G4 is used as a default mobile device for the Chrome Lighthouse plugin and also used by SpeedCurve tests, being the fourth most popular mobile device in the crawling space.
| Moto G4 User-Agent samples |
|---|
| Mozilla/5.0 (Linux; Android 7.0; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4590.2 Mobile Safari/537.36 Chrome-Lighthouse |
| Mozilla/5.0 (Linux; Android 8.1.0; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Mobile Safari/537.36 PTST/220513.185401 |
Google (LG) Nexus 5
- Proportion of reference traffic: 4 % - 7 %
- Reported Android versions: 4.2.1
- Year released: 2013
- Viewport width: 360 (1080 physical)
- Diagonal screen size: 5”
- Processor: Quad-core (2.3 GHz)
- Used by Google
Mainly used by Google Web Light service which is used to optimize web pages for users with slower internet connections. Using quite old Android (4.2.1) and Chrome versions (38.x). The use of this crawler / service seems to be continuously quite decreasing over time.
| Nexus 5 User-Agent samples |
|---|
| Mozilla/5.0 (Linux; Android 4.2.1; en-us; Nexus 5 Build/JOP40D) AppleWebKit/535.19 (KHTML, like Gecko; googleweblight) Chrome/38.0.1025.166 Mobile Safari/535.19 |
| Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5 Build/MRA58N) AppleWebKit/537.36(KHTML, like Gecko) Chrome/69.0.3464.0 Mobile Safari/537.36 Chrome-Lighthouse |
Generic Android
- Proportion of reference traffic: 6 % - 7 %
- Reported Android versions: 5.0 and 7.0
- Year released: unknown
- Viewport width: unknown
- Diagonal screen size: unknown
- Processor: unknown
- Used by PetalBot and Bytespider
There are also some crawlers using generic Android User-Agents without any model information. This might once become a standard if the adoption of Client Hints properly kicks off. You can find more information about the Client Hints in our Resources section.
| Android User-Agent samples |
|---|
| Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot) |
| Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; https://zhanzhang.toutiao.com/) |
Reference tablets
For a given period there was a very limited use of tablet User-Agents by crawlers (below 1 % of all crawlers traffic) and none of it by the big search engine players like Google or Bing.
Apple iPad
| Apple iPad User-Agent samples |
|---|
| Mozilla/5.0 (iPad; CPU OS 12_4_1 like Mac OS X) adbeat.com/policy AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.2 Mobile/15E148 Safari/604.1 |
| Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1 (compatible; woorankreview/2.0; +https://www.woorank.com/) |
Various Android tablets
| Android tablet User-Agent samples |
|---|
| Mozilla/5.0 (Linux; Android 7.0; SM-T827R4 Build/NRD90M) adbeat.com/policy AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.116 Safari/537.36 |
| Mozilla/5.0 (Linux; Android 5.0.2; SAMSUNG SM-T550 Build/LRX22G) adbeat.com/policy AppleWebKit/537.36 (KHTML, like Gecko) SamsungBrowser/3.3 Chrome/38.0.2125.102 Safari/537.36 |
| Mozilla/5.0 (Linux; Android 6.0.1; SGP771 Build/32.2.A.0.253; wv) adbeat.com/policy AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/52.0.2743.98 Safari/537.36 |
Web crawlers detection
With DeviceAtlas you can identify non-human traffic (robots, crawlers, checkers, download agents, spam harvesters and feed readers) in real-time. You can then decide how to act on this information, whether to block all undesired bots at the door, or just treat them in a different way to legitimate human visitors.
Read more about bot detection and how it can help your business to:
We also have some handy resource lists such as a list of User Agents for the most popular smartphones and devices and the most common mobile browsers across 35 countries.